Global Data Deduplication
Backup deduplication is a method of reducing backup size by eliminating duplicate data blocks from the backup. In most environments, VMs contain repeated data, such as VMs deployed from the same template, VMs running the same operating system, or VMs that share identical or similar files, including database records. Block-level backup deduplication reduces backup size by storing only unique data blocks in the Backup Repository while replacing duplicate blocks with references to the existing ones.
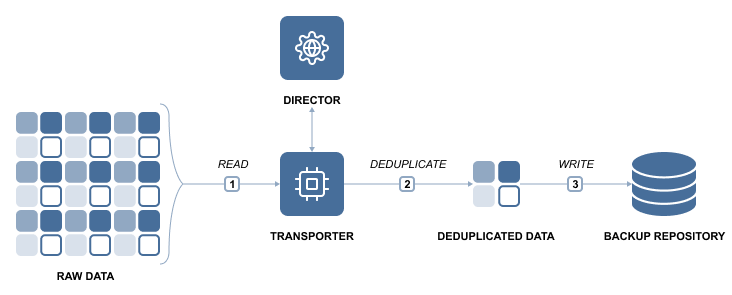
NAKIVO Backup & Replication automatically deduplicates all backups stored in a forever-incremental Backup Repository when this feature is enabled. This means that all data blocks are considered for backup deduplication, even when VMware VMs, Hyper-V VMs, and Amazon EC2 instances are backed up to the same Backup Repository. Global deduplication can be enabled during the Backup Repository creation process. Alternatively, you can use a hardware-based data deduplication device, such as EMC Data Domain, instead of enabling deduplication at the repository level.
Note
The backup deduplication method can be enabled/disabled during the Backup Repository creation process. For details, refer to one of the Creating Backup Repositories sections.
VM backup deduplication can provide a 10X to 30X reduction in storage capacity requirements. For example, you have 10 VMs running Windows Server 2016, which occupies 10 GB each. While the total amount of data is 100 GB, only one copy of OS data (10 GB) will be written to a backup repository with data deduplication, which provides 10 to 1 storage space savings.
More efficient disk space utilization allows for storing more recovery points per VM backup. In addition, lower storage space requirements save money on direct storage costs (as fewer disks are needed to store the same amount of information) and on related costs (such as cooling, electricity, and maintenance).