How Forever Incremental Backups Are Stored
Product version: 10.6
Last modified: 1 December 2021
Questions
I use the forever incremental Backup Repository type ("Store backups in separate files" not enabled).
After opening the folder where my Backup Repository is located, I can see that there are several folders and many files, but I cannot find individual backups.
-
What is the format used to store my backups?
-
Where is my incremental file chain?
-
Can I find a particular backup in the Backup Repository folder?
-
Can I manually extract a single backup from the Backup Repository?
-
Can I calculate the size of the recovery points?
Answers
-
A forever incremental Backup Repository uses the proprietary format for storing block-level data.
-
When using this Backup Repository type, all backed-up data blocks get arranged into a limited number of files for each machine: one full backup file and one file for each increment.
-
A single backup cannot be found in the Backup Repository by name or extracted manually. Backups in this type of Backup Repository are forever incremental. After the first full backup, all subsequent backups accumulate the changed data; periodic full backups are not required. The solution uses synthetic mode to store backup data: After each backup, NAKIVO Backup & Replication creates a recovery point, which references all the blocks required to reconstruct the VM (instance) as of this recovery point. If the amount of changes in a 100 GB VM is just 500 MB, only 500 MB of new data will be added to the Backup Repository. However, the new recovery point will reference the complete set of blocks which are required to restore the entire VM as of this recovery point.
-
All data blocks are shared across different recovery points and backups. If deduplication is enabled, one block may belong to multiple objects. Also, the size of each recovery point can change when some other backups/recovery points are added or deleted. For these reasons, it is not possible to calculate the size of a recovery point.
Example
Here is a simplified example of a forever incremental Backup Repository.
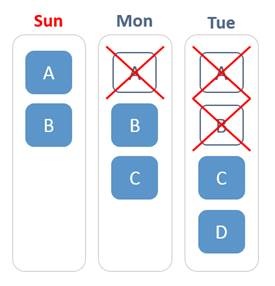
Let’s say the backup for a certain VM runs every day. For the sake of simplicity, we will assume that the VM initially has only 2 data blocks: A and B.
-
The first (full) backup runs on Sunday. Blocks A and B are backed up.
-
On Monday, the incremental backup finds that block A has been removed from the VM, while a new block C has been added to the VM. Block C is backed up.
-
On Tuesday, the incremental backup finds that block B has been removed from the VM, while a new block D has been added to the VM. Block D is backed up.
Here is how the original VM would actually look on each of the three days:
And here is how the recovery points of this VM would be stored in the Backup Repository:
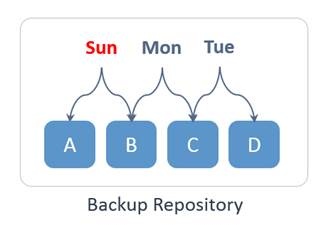
If you delete the Monday recovery point via the NAKIVO Backup & Replication interface, no data blocks will be removed from the Backup Repository, as blocks B and C are also referenced by Sunday and Tuesday’s incremental backups.
Note
All data blocks are stored in the files in the “raw” folder inside the “NakivoBackup” folder. The blocks inside each file may belong to multiple VMs and recovery points. Information about backups and their recovery points is stored in folders named after the UUID of each backup. Global metadata of the Backup Repository is stored inside the “.desc” and “.desc2” files.
Important
Do not modify or delete any files inside the “NakivoBackup” folder. Modifying or deleting any file of the Backup Repository may damage your backups.